Why this exists
Every 13F tracker I’d seen flattened the same point: here are the funds, here are the holdings, here’s a snapshot. But what I actually wanted to know was simpler: what shifted last quarter? New positions, full exits, big adds, big trims. The static portfolio is supporting context; what moved is the story.
So I built a tracker that foregrounds change. Each fund’s page leads with the latest quarter’s diff: new buys at the top, exits underneath, sized changes after that. The current portfolio is a click away, but it’s not the headline.
What it does
Currently tracks two funds:
- Situational Awareness LP: Leopold Aschenbrenner’s AI/AGI-thesis fund
- Duquesne Family Office LLC: Stan Druckenmiller’s generalist macro/value office
For each fund:
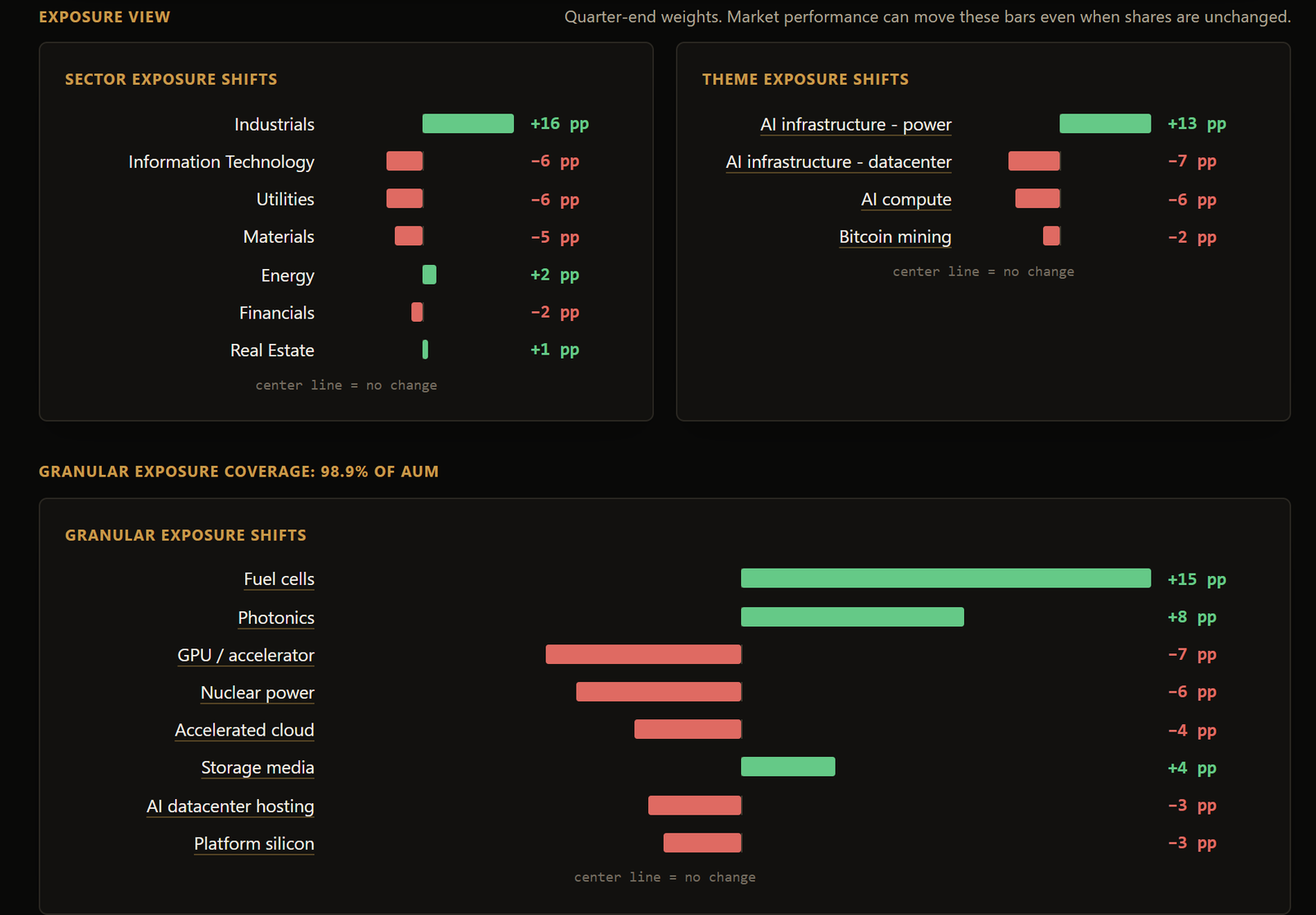
- A changes-first quarter page: new positions, exits, percentage moves, sized for at-a-glance scanning
- An editorial summary I write for each new filing, calling out the thematic pattern (e.g. “rotated harder into compute infrastructure”)
- A per-position thematic tag layer over the raw holdings, so you can see “this fund’s AI-infrastructure sleeve grew 18% this quarter” as a derived view, not just a list
How it works
Three layers, each with a clear job:
- Collect: A daily GitHub Action polls SEC EDGAR for new 13F-HR filings during the four 45-day windows when filings are due. New filings get appended to a pending queue.
- Review: A weekly Resend email reminds me when the queue is non-empty. I open the project in Claude Code and run
/update-quarter, which fetches the new filing, classifies any new CUSIPs (sector/industry via OpenFIGI + Yahoo), prompts me for thematic tags on new positions, drafts the editorial summary, and stages everything for one commit. - Render: Astro builds a static site from the JSON data, deployed to Cloudflare Workers. Every page is generated at build time; no runtime data fetching.
The whole point of the pipeline shape: Claude doesn’t run when a visitor loads the site. Claude only runs during the quarterly review, on data I see and approve before it lands.
Choices that mattered
JSON files as the source of truth, no database. Every fund, every filing, every diff is a file in the repo. Diffs are derived deterministically from raw holdings; when I want to recompute them with a tweaked algorithm, I just rerun the build. No migrations, no schema versioning.
Diffs computed at build time, not stored as the source. The “changes” view is a derived projection. I can change how diffs are computed (per-position thresholds, percent-vs-shares framing) without rewriting any historical data.
One slash command for the whole quarterly loop. Earlier drafts had separate commands for fetch, classify, tag, and summarize. Combining them into /update-quarter cut the per-quarter work to ~20 minutes start-to-finish; short enough that I’ll actually do it on the weekend it’s due.
What’s next
- More funds. The infrastructure is fund-agnostic; adding one is mostly a CIK lookup and a new entry in
funds.json. The next adds are likely a value-oriented fund and a tech specialist, picked for contrast with what’s already tracked. - A cross-fund view. Right now each fund has its own changes page. A page that shows “what did this set of funds collectively add this quarter” would surface the consensus moves vs. the contrarian ones.
- Tag-driven dashboards. The thematic tag layer is in place but underused; once a couple more quarters land, “AI infrastructure exposure across all tracked funds, by quarter” becomes a one-page chart.
Status
Shipped. The poller runs daily; the reminder email lands weekly when there’s a filing to review; the quarterly cadence is real. Two funds tracked through the most recent filing window.